当前全球 AI 大模型领域已形成鲜明的路线分野:中国开源,美国闭源。
中国 AI 企业普遍采用开源策略,阿里通义千问 Qwen、智谱 GLM、DeepSeek 等主流模型均开放权重与推理代码;而美国前沿模型如 OpenAI GPT-5、Anthropic Claude 4.5、Google Gemini 等则以闭源为主,仅通过 API 接口提供服务,不公开核心权重与训练细节。
大模型开源闭源,本质上是SaaS(software as a service,软件即服务)市场现状的延申。
- 美国市场的SaaS更愿意接受云服务、订阅制,比如说Office 365的云协作,并不觉得有什么问题。
- 中国的软件服务,尤其是国企、政府喜欢私有定制解决方案、本地部署,不放心把数据放在别人那里。
所以大模型现在也变成这样。对美国企业来说,我用 ChatGPT企业版 ,用 API 都有保密条款,不会把我的数据拿去训练数据,没有什么不妥的。直接看OpenAI官网的条款就好了,凡是商用版本的,都默认不用于训练。

对于中国企业来说,自己没啥三瓜两枣,但就是不放心把数据给你。所以数据必须要在我自己的服务器上,不能发送到外部云。
这个心态的背后就复杂得多。只要不是外宾,是个中国人,都知道用微信没有任何隐私可言。国内企业拿你的数据去训练也是惯用做法,不存在底线,保密条款都形同虚设。
但对于绝大多数美国企业来说,几乎没有这样隐私的担忧,用云,用ChatGPT企业版,用API,都是和吃饭喝水一样的正常。而一家做零售的企业,自身的大模型人才储备远远不够,选择让专业的人做专业的事情,直接采购OpenAI、Anthropic的LLM服务才是最低成本的选择。
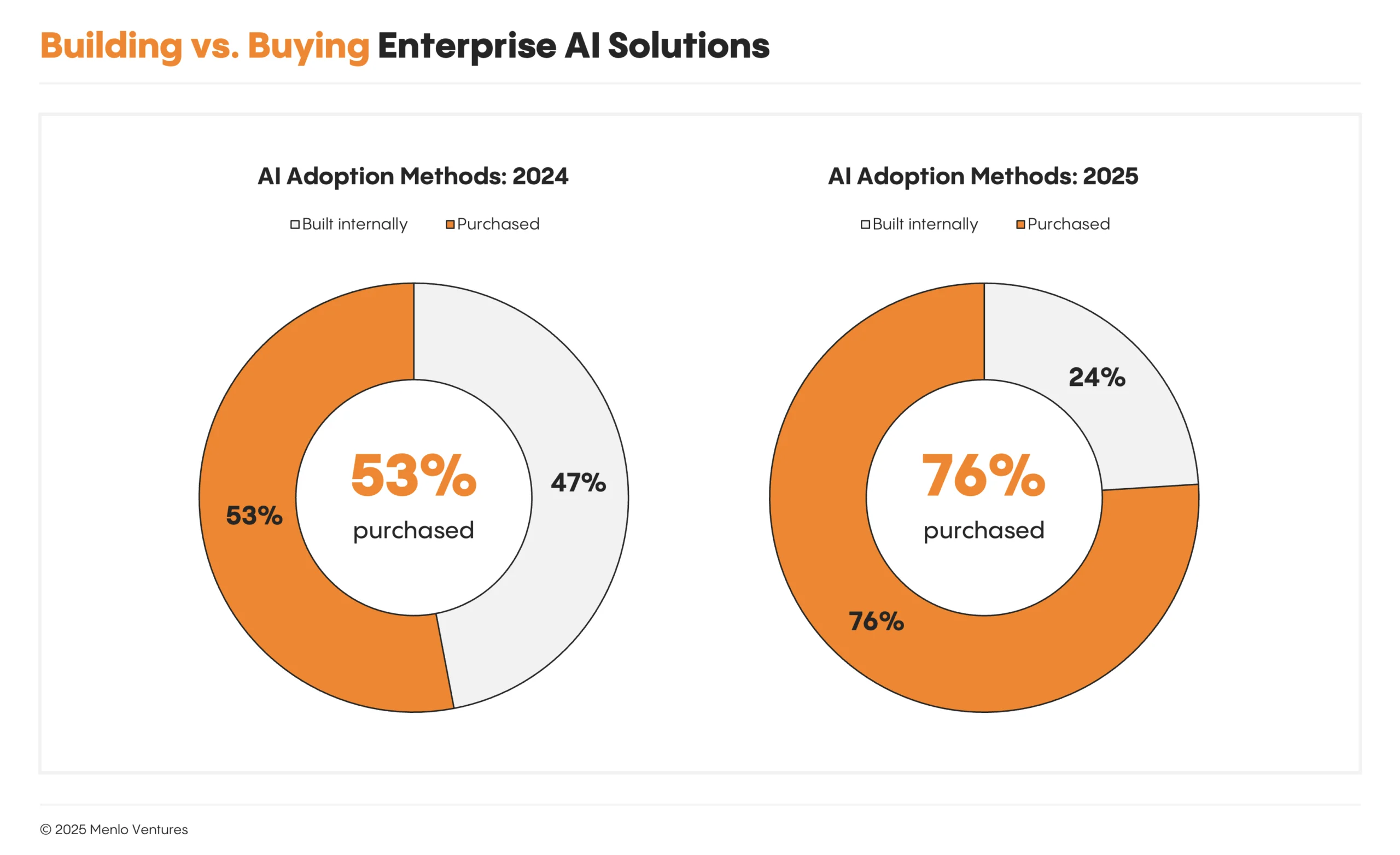
2025年年底,Menlo Ventures的调研显示,美国企业市场对大模型,出现了造不如买的风潮。比如说2024年,有47%的公司还愿意自己造AI解决方案;到了2025年,只剩下24%愿意自己造,76%都直接买现成的大模型解决方案了。

在未来,极大概率中美之间的差异还会继续分化下去。
发表评论